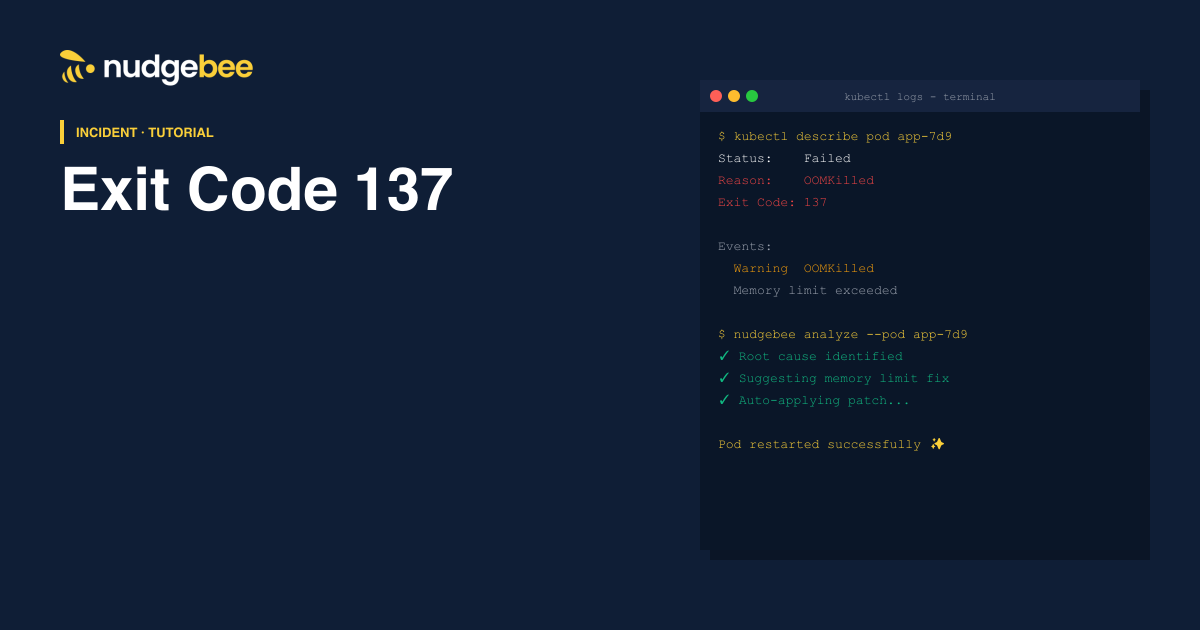
If you’re seeing Exit Code 137 in Kubernetes, your pod was OOMKilled (Out of Memory).
👉 Simple meaning:
- Your container used more memory than allowed
- Kubernetes killed it to protect the node
👉 Quick fixes:
- Increase memory limits
- Fix memory leaks
- Use monitoring (Prometheus / Grafana)
- Add autoscaling (VPA)
What is Exit Code 137?
Exit Code 137 = SIGKILL (Killed process)
In Kubernetes, this almost always means:
👉 Your pod ran out of memory
👉 Kubernetes forcefully stopped it
In simple terms:
Exit code 137 = Your app used too much RAM → system killed it
Why does Exit Code 137 happen in Kubernetes?
Here are the most common reasons:
1. Memory limit is too low
Your pod has a limit like:
resources:
limits:
memory: "512Mi"
👉 If your app needs more → it crashes
2. Memory leak in application
Your app keeps consuming memory:
- unclosed connections
- large caches
- inefficient loops
👉 Eventually → exceeds limit → killed
3. Node memory pressure
Even if your pod is fine:
👉 Node doesn’t have enough memory
👉 Kubernetes kills pods to survive
4. Heavy workloads
Examples:
- large queries
- batch jobs
- big datasets
👉 Temporary spike → pod killed
Fix OOM at the Source
Limits, leaks, or node pressure.
How to Fix Exit Code 137 (Step-by-Step)
Increase Pod Memory Limits
Update your deployment:
Adjust your deployment YAML to allocate more memory.
resources:
requests:
memory: "512Mi"
limits:
memory: "1Gi"
Best for:
- stable apps needing more memory
Be careful:
- don’t over-allocate → node crash risk
2. Fix Memory Leaks (Important)
If memory keeps increasing:
👉 You need to fix code, not infra
Use tools:
- pprof
- heap dumps
- Prometheus metrics
Check:
- large objects
- open connections
- unnecessary caching
3. Use Vertical Pod Autoscaler (VPA)
Automatically adjusts memory
Best for:
- unpredictable workloads
4. Monitor Memory Usage
Don’t wait for crash.
Use:
kubectl top pods
Or:
- Prometheus
- Grafana
Set alerts when usage > 80%
Automatically adjusts pod resource requests and limits.
Pro Tip
Don’t only increase memory blindly
If you don’t fix root cause:
problem will come back
Let VPA Right-Size
Auto-tune requests and limits.
Troubleshooting Checklist
Before fixing, check:
- Pod events → kubectl describe pod
- Logs → kubectl logs
- Node usage
- Confirm OOMKilled status
Quick Fix Reference Table
| Fix | When to Use | Risk |
|---|---|---|
| Increase memory limits | Stable app, just under-provisioned | Node exhaustion |
| Optimize code | Memory leaks suspected | Slower to implement |
| VPA | Dynamic workloads | Overhead |
| Monitoring | Continuous issues | Setup effort |
Cut MTTR for Pod Crashes
Guided workflows, fast recovery.
How NudgeBee Helps
Exit Code 137 errors often slow down SRE teams. NudgeBee’s AI-powered SRE Assistant helps you:
- Detect pods nearing OOMKilled before they crash.
- Recommend fixes automatically.
- Reduce MTTR with guided workflows.
FAQs
What is Exit Code 137 in Kubernetes?
It means your pod was OOMKilled, terminated due to exceeding memory limits.
Is Exit Code 137 always memory-related?
Yes. 137 specifically indicates a memory kill (SIGKILL).
How do I prevent Exit Code 137?
1. Set realistic memory requests/limits.2. Monitor memory usage with Prometheus.3. Use VPA for dynamic workloads.
Can restarting a pod fix Exit Code 137?
Sometimes. A restart clears memory, but the underlying issue will return if not fixed. See: 4 ways to restart a Kubernetes pod.